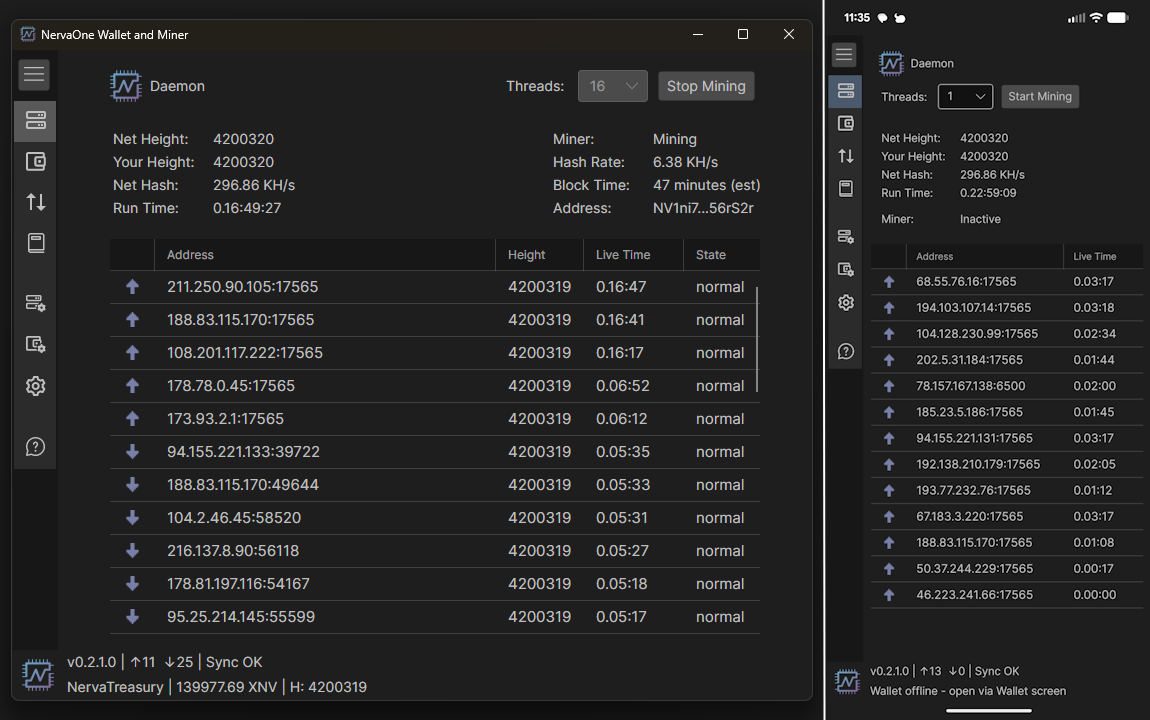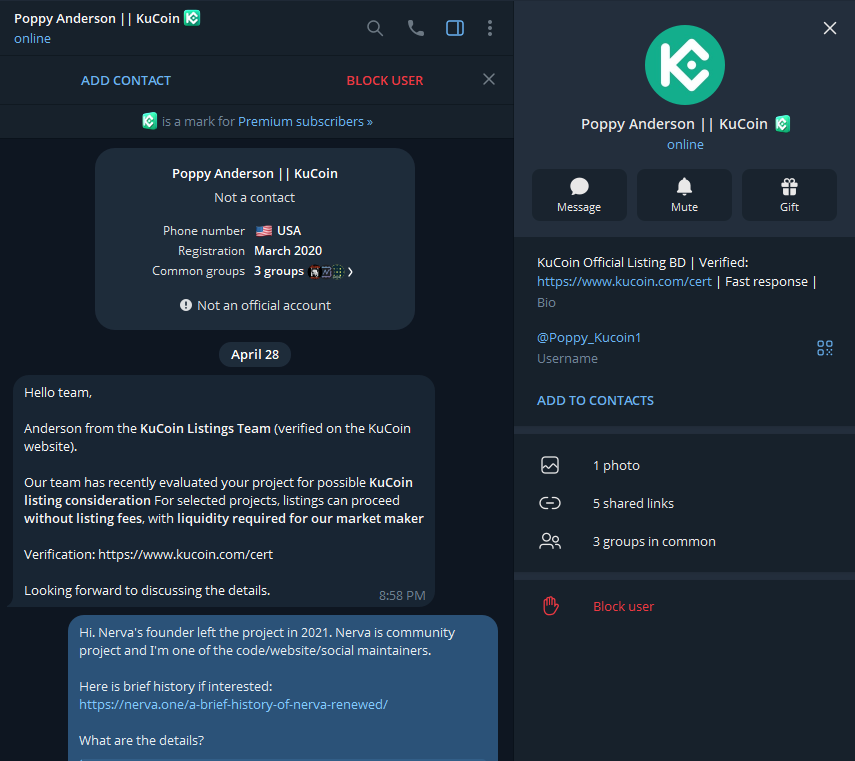
There are so many scammers in crypto. You have to be very careful out there. Here is Poppy Anderson supposedly from KuCoin, @Poppy_Kucoin1. The day of this conversation, this user ID validated on https://www.kucoin.com/cert. The next day, it was no longer validating.
He probably did not expect me to be able to submit the application and wanted me to come back to him for help, at which point he would probably offer “other solution”. Well, half a day after my last message, he deleted this conversation from Telegram which 100% confirms to me that this was scam attempt.
Wen Nerva on KuCoin? 😁
Poppy Anderson || KuCoin
28 April 2026
20:58
Poppy Anderson || KuCoin
Hello team,
Anderson from the KuCoin Listings Team (verified on the KuCoin website).
Our team has recently evaluated your project for possible KuCoin listing consideration For selected projects, listings can proceed without listing fees, with liquidity required for our market maker
Verification: https://www.kucoin.com/cert
Looking forward to discussing the details.
21:27
Rob Coder
Hi. Nerva’s founder left the project in 2021. Nerva is community project and I’m one of the code/website/social maintainers.
Here is brief history if interested:
https://nerva.one/a-brief-history-of-nerva-renewed/
What are the details?
❤
21:31
Poppy Anderson || KuCoin
Nice to meet you
21:31
KuCoin continues to rank among the top exchanges on CoinMarketCap,
So I believe you’re already familiar with our platform.
21:32
Rob Coder
Yes, I’ve used KuCoin a while back.
❤
21:32
Poppy Anderson || KuCoin
We are proposing a listing without any listing fees. We only ask for liquidity to support our market maker for 1 month.
KuCoin will use this liquidity during the period to provide smooth trading.
After the 1 month is completed, the full liquidity will be returned, and your token will remain listed on our spot market permanently.
21:33
So which pair u prefer for listing with Nerva?
21:33
Rob Coder
What are the liquidity requirements?
21:34
Poppy Anderson || KuCoin
We just intial liquidity to create trading pair and once token get listed u can add more liquidity
So initial required LP for USDT pair would be
5k to 10k Usdt + Equivalant in tokens
21:34
We will manage the liquidity first 30 days then we send back LP funds to original wallet and u can start ur own MM
21:34
We will do massive marketing before listing date
21:35
Rob Coder
Yeah, raising $10k – $20k might be a problem. The community is still small.
21:36
Poppy Anderson || KuCoin
How much can be done from ur side for the start
21:36
We just need to create trading pair first
21:37
Rob Coder
Why can’t trading pair be created with $500 + $500 in XNV? Why does it need to be this high?
21:38
Poppy Anderson || KuCoin
For smooth start so we can raise price organically but since its community driven and volume still small we can accept small amount just to create the trading pair
21:39
Plz confirm
21:39
Rob Coder
If it’s $500 USDT + $500 XNV, that would work.
21:40
Poppy Anderson || KuCoin
And once token get more volume after listing u can add more liquidity
We will do marketing for free
21:41
So announcement will be done within 2 hours after application done
Listing will be done within 5 days after announcement
21:41
Rob Coder
How can I confirm that this is legit offer through official KuCoin website?
21:42
Poppy Anderson || KuCoin
Sure u can verify me at kucoin verification page at our official website
21:42
21:42
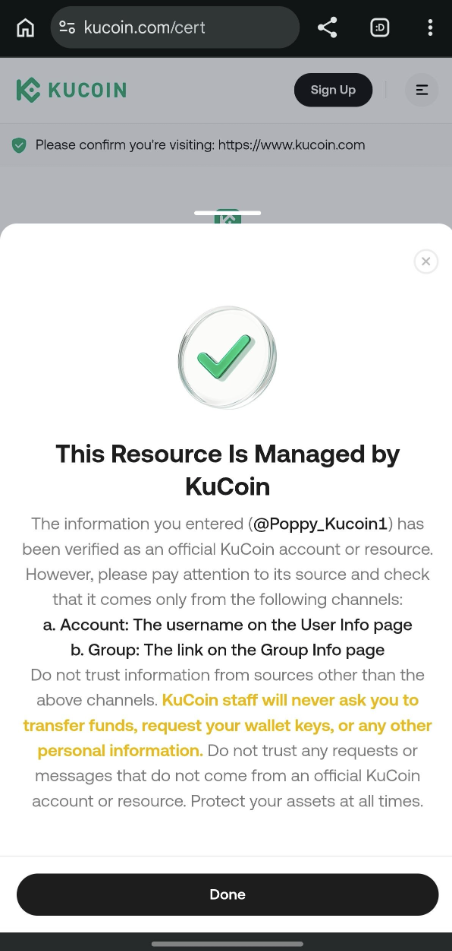
21:42
Please check and confirm
21:44
Tell me once checked to proceed with steps of application
21:45
Rob Coder
I verified already but this sounds too good to be true so I’d like additional verification through official website or official X account .
21:45
Poppy Anderson || KuCoin
Just to clarify – we never use Twitter or emails for verification.
Those are only for announcements and updates.
That’s why kucoin has its official Verification Page, where you can check any real admin username directly. It’s the only secure and trusted method to confirm real kucoin representatives and avoid any impersonation.
21:45
We can send u an email from our official domain as second Verifcation
21:46
Rob Coder
Is the application submitted through the website?
21:47
Poppy Anderson || KuCoin
Yes for sure
21:47
Rob Coder
OK, so where do I go to submit the listing application?
21:48
Poppy Anderson || KuCoin
the listing process is very simple:
1] Fill out the official KuCoin application form.
www.kucoin.com/listing
2 We’ll send the signed agreement for your confirmation.
Transfer the required LP amount as stated in the agreement.
4 KuCoin will announce the listing and start the marketing campaign.
21:48
I will follow step by step until application done
21:48
Hope steps are clear please read and confirm
21:51
Rob Coder
Yes, steps are clear. As long as application goes through the website and I’ll get confirmation from kucoin.com email that I can reply to, I think that’s good enough.
21:52
Poppy Anderson || KuCoin
Sure
21:55
Rob Coder
OK, I will fill out the application tomorrow. Do I need to put anything specific in there or just fill out what it’s asking for?
21:55
Poppy Anderson || KuCoin
Just fill what its asking
If u have any question about the form let me know to help thanks
👍
29 April 2026
08:33
Rob Coder
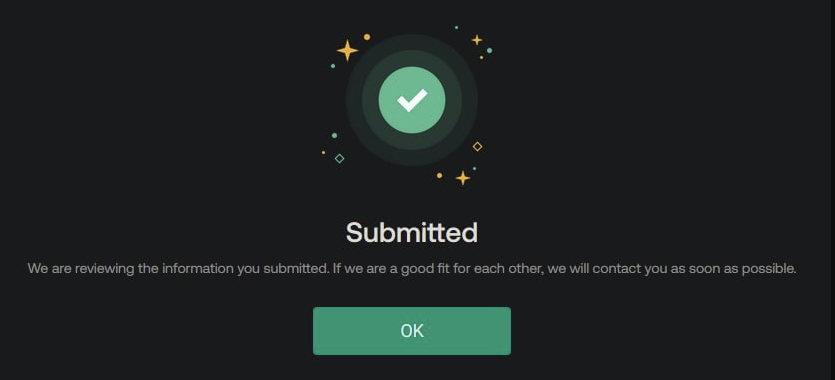
Submitted.