NERVA (XNV) is a privacy cryptocurrency where your transactions are completely private.
Sender, receiver, and amount are all hidden on the blockchain, so your financial history stays yours alone.
Built on proven Cryptonote technology, NERVA works like digital cash: spend it without leaving a trace.
NERVA uses CPU-only Proof of Work mining with no pool support. Each miner participates independently, which creates strong decentralization and makes the network censorship resistant.
Its Cryptonight Adaptive algorithm resists ASIC and GPU mining rigs, ensuring anyone with a regular computer can take part and help secure the network.
NERVA's exclusive Cryptonight Adaptive algorithm resists ASIC and GPU mining. Combined with no pool support, every miner competes individually, keeping the network truly decentralized.
Fair Launch
NERVA launched with no ICO and no investor allocation. A 1% premine went to the project's creator, who left in 2021. All other coins have been earned through mining.
Energy efficient
No need for expensive GPU rigs or specialized hardware. Mine on your existing computer using resources you already have.
Fast transactions
One minute block time means your funds arrive quickly.
Fast transactions, combined with low fees, allow you to send and receive NERVA quickly and cost effectively.
Private by Default
Every NERVA transaction hides the sender, receiver, and amount on the blockchain by default. Your financial activity is private without any extra steps.
Fair distribution
With CPU-only mining and no pool support, no single entity can dominate the network. Every miner participates on equal footing, making NERVA one of the most fairly distributed cryptocurrencies.
Our Mission
1
Crypto for everyone
Crypto should be accessible to everyone, not just those who can afford specialized hardware.
NERVA lets you mine on any standard computer, no elaborate setup required.
True decentralization means anyone can participate. Read More
We back this up with actively maintained software. A PHP API lets developers integrate NERVA into their projects.
NervaOne, our open-source desktop wallet and miner, makes it easy to get started on Windows, Linux, and Mac.
The NERVA community is active on Discord and Telegram, with people always around to help.
This is a community-driven project where every miner, trader, and holder is treated equally,
working together to keep crypto decentralized and in the hands of individuals.
2
On the cutting edge
NERVA takes a different approach to cryptocurrency.
With a custom Proof of Work algorithm, solo CPU-only mining, and a fixed emission curve,
NERVA challenges conventional thinking about how blockchains are mined and secured. Read More
NERVA was the first cryptocurrency to demonstrate a self-adjusting mining algorithm, changing parameters every block.
Cryptonight Adaptive is now in v12, with v13 in development. Every hash relies on randomly selected blockchain data,
making the network highly resistant to ASICs, FPGAs, and rented hash services like NiceHash,
providing strong protection against 51% attacks that have compromised other blockchains.
NERVA also completed a milestone no other Cryptonight blockchain had reached: the end of primary coin emission.
After approximately three years, the network entered tail emission, a small steady block reward designed to
replace lost coins and keep miners incentivized. NERVA proved this transition works, providing a real-world
example for other projects to learn from.
3
A simple use case
Our use case is simple. To provide a stable blockchain with fast, low fee transfers
usable by anyone with a straightforward, no nonsense interface.
To provide the tools and resources to assist developers to integrate NERVA into
their systems and use NERVA as an alternate payment method. Read More
NERVA provides APIs and developer tools for anyone who wants to build with it,
whether that's integrating payments, building applications, or using NERVA as an in-game currency.
For non-developers, NervaOne makes it easy to store, send, and mine NERVA on any computer.
We continue working to expand exchange listings and make NERVA easier to buy, sell, and use.
Node Map
Nerva is decentralized through CPU-only mining and no pool support. Every miner operates a full node, making the network extremely resistant to 51% attacks. 1 CPU = 1 Vote, as described in the Bitcoin whitepaper.
Nerva's Roadmap
The Future
Future
Community Driven
Nerva is an open-source project with no company, no roadmap handed down from above. What gets built next depends on what the community wants to build. If you have ideas, skills, or just the will to contribute, this project is yours to shape. The future of Nerva is unwritten, and that is intentional.
2026
Q4 / 2026
Hard Fork 14 In Development
Nerva's next planned network upgrade, currently in active development. Three key improvements: stronger transaction privacy through a larger anonymity set; smaller and faster-to-verify transactions via more efficient cryptographic signatures and proofs; and a new mining algorithm that further deepens the memory-bound approach introduced in HF13, keeping mining fair and ASIC/GPU resistant, upholding Nerva's one CPU, one vote principle.
Q3 / 2026
Hard Fork 13 Completed
Network upgrade including a redesigned mining algorithm with stronger GPU and ASIC resistance, keeping Nerva CPU-only and pool-resistant, as it has always been. Also included: daemon sync improvements for faster node setup.
Q2 / 2026
Software Development Completed
Research and evaluate core software updates aligned with Nerva's long term goals. Begin development on new releases and continue improving existing Nerva services and infrastructure.
Q1 / 2026
Community Growth Ongoing
Launched a new Nerva subreddit and continued growing the broader community through engagement, education, and outreach initiatives.
Q1 / 2026
Exchange Expansion Ongoing
Following the 2025 delistings from XeggeX and TradeOgre, Nerva secured new listings on NonKyc and several smaller exchanges, restoring liquidity and market accessibility.
2025
Q1 / 2025
Grow Nerva's X Presence
Continue grinding on X and growing Nerva's account.
2024
Q4 / 2024
Release NervaOne Mobile
Develop, test and release a working version of NervaOne Mobile. Put on hold. Community growth was prioritized over mobile development at the time.
Q3 / 2024
Start working on phase 2 of NervaOne
NervaOne Desktop was developed and it replaced Nerva's old GUI. It's an open-source, non-custodial, multi-coin wallet and miner that currently supports $XNV, $XMR, $WOW and $DASH.
Start working on phase 2: mobile wallet that connects to your NervaOne Desktop to provide mobile wallet functionaity without the need to trust 3rd party.
Q2 / 2024
Create new GUI application
Our desktop application is build using no longer supported dotnet 5 technology and some people are having issues running it, especially on Linux and Mac.
Create new, slick looking desktop application that will run on Windows, Linux and Mac.
Q2 / 2024
Pursue more exchange listings
Try to get listed on 3rd exchange or a DEX.
Q1 / 2024
Grow Nerva's community
Continue building Nerva's community by engaging with current users and trying to attract new users.
Start doing more giveaways.
Continue sharing Nerva's vision of privacy and security.
Try to help make crypto more accessible to everybody.
2023
Q4 / 2023
Get listed on 2nd exchange
Get Nerva in front of new users by allowing them to trade on another exchange.
Q4 / 2023
Build X (Twitter) presence
Reach new users by sharing posts related to crypto, privacy and mining on X (Twitter), expanding Nerva's presence and user awareness.
Q2 / 2023
Mobile and Web Wallet
Nerva was added to DogeCash App, a custodial mobile and web wallet service. It's available in Google Play Store and Apple App Store.
2022
Q1 / 2022
Desktop Wallet Improvements
Desktop wallet (GUI) got stability improvements and one click miner button was added.
2021
Q4 / 2021
XNV Treasury Buybacks
Continue the XNV Treasury buyback via Tradeogre. 100100 Coins are currently in the Treasury Wallet.
Q4 / 2021
Rebrand to a New Domain
Set up Nerva services on nerva.one domain, release new version of Nerva software and update outside links.
Q4 / 2021
Bitbucket to Github Migration
Migrate the Nerva Bitbucket repository to Github making it accessible to more developers.
To check a paper wallets balance you have to restore the wallet: Restoring a wallet There is no way to check a balance offline because nerva is a privacy coin.
There will be around 18.5 million coins issued before "tail emission" occurs, which is a small 1% annual inflation to keep miners incentivized, replace lost coins and provide future liquidity.
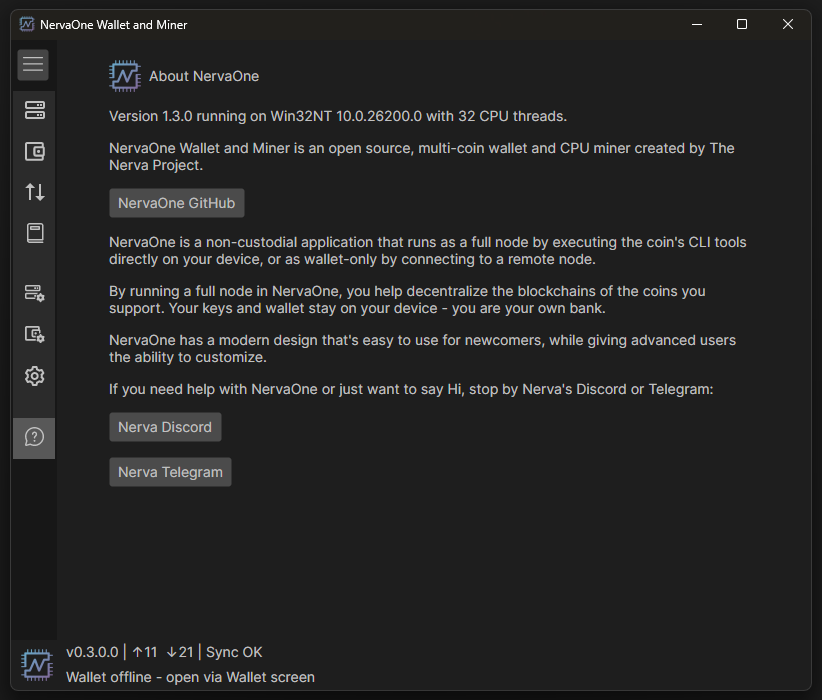
NervaOne v1.3.0 is now available for Windows, Linux, macOS, and Android. It gets your node ready for Nerva’s mandatory hard fork, adds a new mining affinity option, and includes security improvements across all supported coins.
Ready for the Nerva hard fork
Nerva’s hard fork, v0.3.0.0 “Legacy Remade,” activates at block 4,320,000 (around July 21, 2026) and is mandatory. NervaOne v1.3.0 points to the new v0.3.0.0 daemon. Once you have the updated NervaOne, install it by going to Daemon Setup > Update Client Tools > Update. New users just download v1.3.0. Either way, update before the fork.
Mining affinity
NervaOne can now pin mining threads to physical CPU cores for a higher and more stable hashrate, even while you use your PC. Find the toggle under Daemon Setup > Pin mining threads to CPU cores (affinity) – on by default on desktop, off on Android. Mining with the CLI directly? Add the --mining-affinity flag to your mining command.
Security and other improvements
Wallet credentials and payment IDs now use a cryptographically secure random number generator
Password required when creating or restoring BTC-based wallets
Fixed precision loss in atomic-unit to amount conversion
Get NervaOne v1.3.0 from the downloads page or from GitHub. Each release includes a GPG-signed list of SHA256 hashes – we recommend verifying your download against it. NervaOne is open source and non-custodial; your keys never leave your device.
Today we’re releasing Nerva v0.3.0.0 “Legacy Remade”, and it carries our most significant network upgrade in a very long time. This is a mandatory hard fork. Every node operator, miner, service, and wallet user needs to update. If you run any Nerva software, this post is for you.
The fork activates at block 4,320,000, approximately July 21, 2026 (around 19:00 UTC).
If you have not upgraded by that block, your node stops following the real Nerva network.
Please don’t wait for the deadline. Upgrade early, confirm your node is happy, and you’re done.
1 CPU = 1 Vote
Nerva has always stood for one idea, the one Bitcoin was founded on and then drifted away from: one CPU, one vote. Mining should stay in the hands of ordinary people running ordinary CPUs. No ASIC farms, no FPGA racks, no GPU cartels, and no pools concentrating hashpower into a handful of operators. On Nerva there are no mining pools, by design. Every miner mines solo, directly on the network, on equal footing.
Keeping that promise means our Proof of Work cannot sit still, because specialized hardware and pooling schemes eventually adapt to any algorithm that never changes. It has been years since our last hard fork, and the hardware landscape has moved on. “Legacy Remade” is us moving with it: honoring what Nerva has always been while rebuilding the core that keeps it fair.
What’s new in this fork
CryptoNight-Adaptive v6, our new Proof of Work. CNA v6 uses an 8 MB memory scratchpad combined with a randomized virtual-machine program, so mining leans on memory latency and general-purpose compute, the things everyday CPUs are good at, rather than the fixed, repetitive work that specialized chips exploit. It keeps Nerva CPU-friendly and pushes back hard against ASIC and FPGA centralization.
Pool resistance, preserved. Nerva’s Proof of Work stays pool-resistant by tying mining to real blockchain data, so work can’t be neatly chopped up and farmed out to a pool the way it can on other coins. In this fork we moved that mechanism to a sliding window of recent blocks, which keeps the pool resistance fully intact while lightening what a miner needs on hand to work.
Much faster initial sync. New nodes now get caught up in minutes rather than hours. For the older, deep history of the chain the daemon trusts the checkpoints baked into the release instead of re-verifying every block from scratch, and it fully verifies the recent blocks near the tip. You get a quick start without giving up safety, and full verification is always available if you want it.
Privacy and consensus hardening. Alongside the new algorithm, this release tightens transaction validation at the consensus level, including a minimum-output rule and stricter requirements on the outputs referenced by ring signatures. These changes strengthen the privacy guarantees of the network going forward.
Closing the gap with Monero
Nerva is built on Monero’s battle-tested privacy technology, and one of our ongoing commitments is keeping our codebase current with the improvements Monero makes upstream. Over recent releases we have been steadily closing that gap, carefully porting performance, security, and stability work from Monero into Nerva while preserving the things that make Nerva its own coin, CPU-only mining and pool resistance.
This release continues that effort. The result is a stronger, more modern foundation under the hood, so Nerva benefits from the wider Monero community’s engineering without ever compromising on what makes Nerva different. Closing the gap with Monero is not a one-time task, it is a direction, and we will keep at it release after release.
We tested this thoroughly
This release did not ship on hope. It ran on public testnet ahead of the mainnet fork, and we verified the things that actually matter to users:
Nodes sync cleanly through the fork.
Mining works on the new algorithm across different CPUs and operating systems, with deterministic, matching results across machines.
Wallet create, restore, and transfer all function correctly before and after the fork.
What you need to do
The action is the same for everyone: replace your old binaries with v0.3.0.0 and restart. Who this applies to:
Miners: Update before the fork or you will be mining invalid blocks that the network rejects. Your work after block 4,320,000 only counts if you’re on v0.3.0.0.
Node operators: Update to stay connected to the network and to keep serving the wallets and miners that depend on you.
Exchanges and services: Update your daemons ahead of the fork to avoid deposit and withdrawal downtime.
Everyday wallet users: Update your wallet software so you can keep sending and receiving after the fork.
Using NervaOne? A new NervaOne release with the updated binaries built in is coming in the next few days. If you’d rather not wait, you can update right now: go to Daemon Setup > Update Client Tools and paste the daemon download URL for your operating system, available on the download page below. If you run the CLI daemon and wallet directly, grab the v0.3.0.0 binaries and swap them in.
This is a big moment for Nerva, and it lands because of the people who run nodes and point their CPUs at the network. One CPU, one vote, still true, still worth defending. Upgrade, tell a fellow Nerva miner, and let’s cross the fork together.
On January 30, 2026, $XNV was listed on the NonKyc exchange. For a lot of projects, a listing is the goal. For Nerva, it was just a checkpoint. Since then, XNV has been added to two more exchanges, CEXSwap and NoirTrade, giving people more ways to trade it. And in the months since, the community has shipped an enormous amount of work, which we wanted to look back on and share.
First, a quick note for anyone new here. Nerva (XNV) is a private, community-run cryptocurrency. It’s mined with ordinary computer processors (CPUs), the kind already in your laptop or desktop, with no mining pools and no expensive specialized hardware. The whole idea is fairness: one person, one CPU, a real vote in the network. There’s no company behind Nerva and no paid team. Everything below happened because people in the community chose to build it.
The core software: four releases and a major upgrade
The “core” is the daemon, the program that runs the Nerva network and validates every transaction. In under six months it saw four public releases, building toward the biggest upgrade in years:
v0.2.1.0 through v0.2.3.0 (April to June): a steady run of improvements, better support for more devices, faster and more reliable syncing, modernized networking, and a long list of bug fixes and safety fixes.
v0.3.0.0 “Legacy Remade” (July): this was Hard Fork 13, a network-wide upgrade. It introduced a redesigned mining algorithm (CryptoNight-Adaptive v6) that’s even more resistant to the specialized machines and GPU farms that centralize other coins, keeping mining fair for everyday CPUs. It also made syncing a new node dramatically faster.
If some of that sounds technical, the short version is simple: Nerva got faster, safer, runs on more devices, and its mining stays fair.
Hard Fork 14: what’s coming next
The next network upgrade, Hard Fork 14, is already in development, and it’s a big one for privacy. Here’s what it brings, in plain terms:
Stronger privacy per transaction. A larger anonymity set means each payment you send is hidden among more possible decoys, making it even harder for anyone to trace.
Smaller, more efficient transactions. Newer cryptographic signatures (CLSAG) and proofs (Bulletproofs+) do the same job as before while taking up less space, which means lower fees and a leaner blockchain.
Even fairer mining. A further-evolved mining algorithm (CryptoNight-Adaptive v7) continues to level the playing field so ordinary CPUs stay competitive and the network stays decentralized.
In short: more private, more efficient, and still fair to mine on any computer.
NervaOne: a wallet and miner that grew up fast
NervaOne is the all-in-one app that makes Nerva approachable: wallet, node, and mining in one place. It also supports several other coins, so it’s a single home for a good chunk of your crypto. This was one of the busiest projects of the last six months, with five releases that transformed what it can do.
v0.8.5.0 (March): remote nodes. Added the ability to connect to a remote node for wallet-only use.
v1.0.0 (April), a major milestone: NervaOne went mobile. Alongside the desktop app, it launched on Android, with a redesigned interface that works on phone and computer alike. It also added a one-tap option to download the blockchain for much faster setup, and made connecting to a public node far simpler. You can run it as a full node or in lightweight wallet-only mode, whatever suits you.
v1.1.0 (May): Bitcoin support. NervaOne added BTC, with full or pruned node options, wallet creation and restore, and a fee preview before you send.
v1.2.0 (June): Litecoin support. Next came LTC (including MWEB), plus stronger security under the hood, encrypted RPC authentication and sensitive credentials scrubbed from log files.
v1.3.0 (July): mining and security polish. A Nerva mining affinity toggle to keep your hashrate steady while you use your PC, cryptographically secure wallet credentials, and precision fixes for rock-solid balances.
That’s a lot in half a year: a mobile launch, two major new coins (BTC and LTC) on top of the Nerva, Monero, Wownero, and Dash it already supported, and a steady march of security and usability upgrades. If you’re new and want the simplest starting point, NervaOne is it.
Nerva Quest: get involved and earn XNV
One of the most fun ways to join in launched in this window: Nerva Quest, a community rewards platform. The tagline says it best: Create. Engage. Earn XNV.
You complete simple quests that help the Nerva ecosystem, Daily Quests and bigger Epic Quests, submit your proof, and claim real XNV as a reward. No email, no KYC, no barriers. It’s the easiest way for a newcomer to earn their first Nerva just by participating.
And the community has run with it: over 600 XNV has already been paid out, across hundreds of completed quests. That’s real rewards going to real people for helping the project grow.
Growing beyond Nerva: new tools and integrations
Nerva also showed up in more places built by the wider crypto community, a sign the ecosystem is reaching outward:
BoxWallet by richardltc, a terminal-based wallet manager that installs, starts, and monitors coin daemons from a single simple interface, with Nerva now among the supported coins.
coinQuests by richardltc, a quest platform where you complete simple social tasks for the coins you follow, Nerva included, and earn payouts.
The public face of the project stayed in step with everything shipping:
nerva.one got a visual refresh, including a new dark mode, a roadmap showing exactly what’s done and what’s coming, live upgrade countdowns, and download links kept current with every release.
docs.nerva.one was rewritten to be accurate and easier to follow, updated guides, current specs, and a clearer explanation of what makes Nerva’s fair, pool-free mining actually work.
Still just getting started
Six months. Four releases. A major network upgrade with another already in development. A maturing wallet. A rewards platform paying out real XNV. New integrations from the wider community. A refreshed website and docs. All of it built by a community, for a community, with no company pulling the strings.
And it doesn’t stop here. Hard Fork 14 is on the way, along with other initiatives the community is actively building. Nothing is handed down from above, what gets built next depends on the people who show up.
If any of this speaks to you, there’s room to help shape it. Come mine, come build, come earn, come say hello on Discord or Telegram.
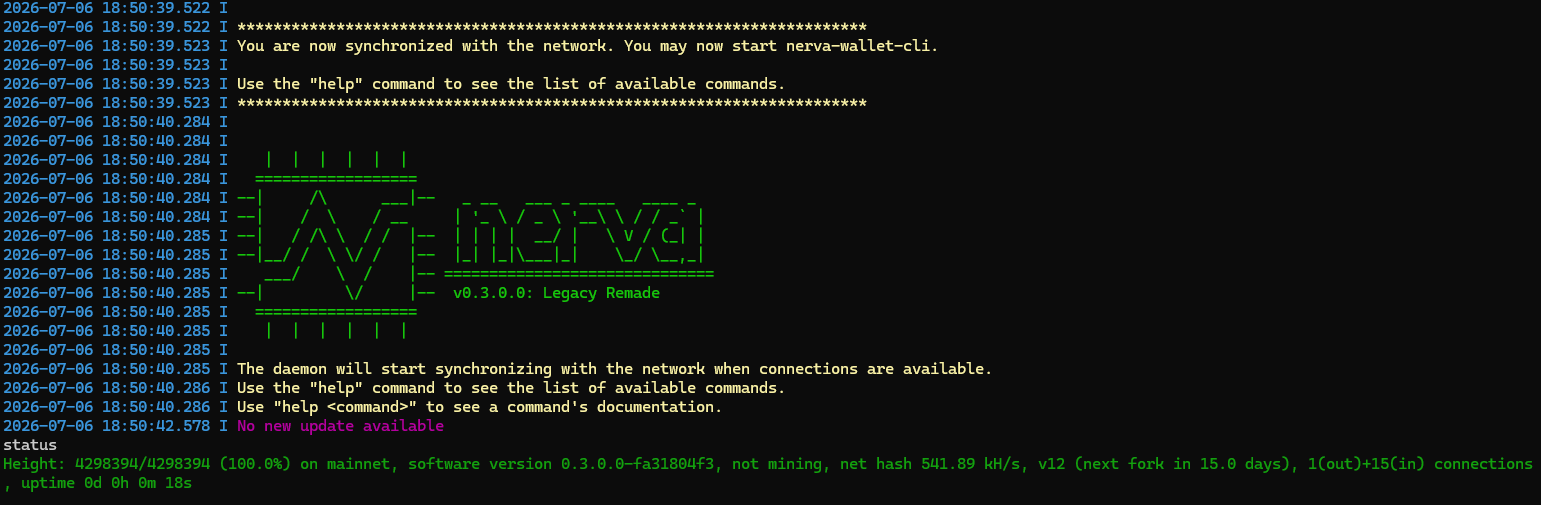
Nerva forked at block 4,320,000 on July 21, 2026, and the network is now running on CryptoNight-Adaptive v6. It went smoothly, and the numbers have already settled.
This was our first hard fork in over six years. The last one was February 6, 2020, at block 930,000. Six years and five months is a long time between forks, and getting a network this old through a Proof of Work change without drama is not a given. It happened because people prepared.
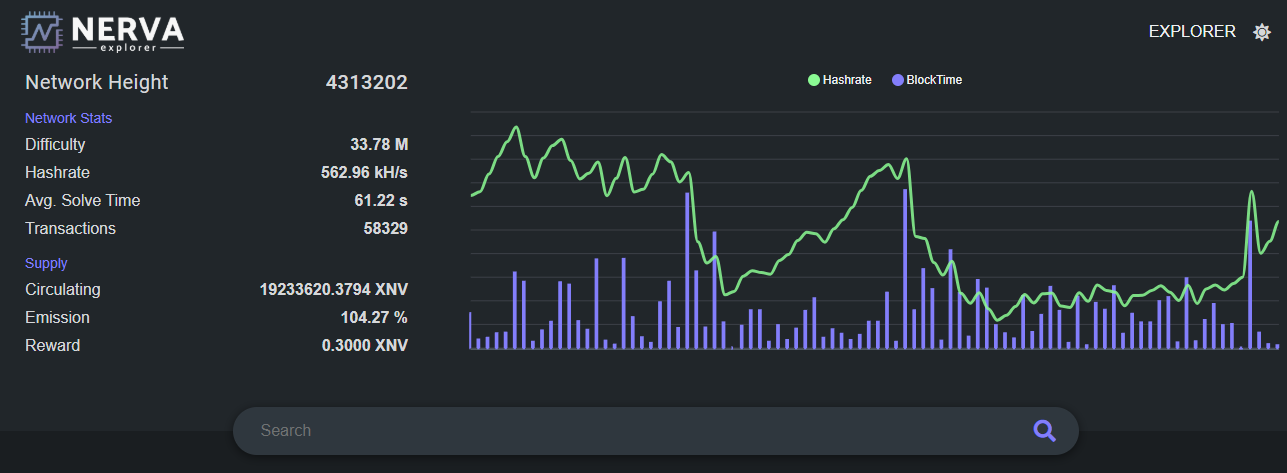
What the numbers look like now
If you glance at the explorer and panic, don’t. Here’s the before and after:
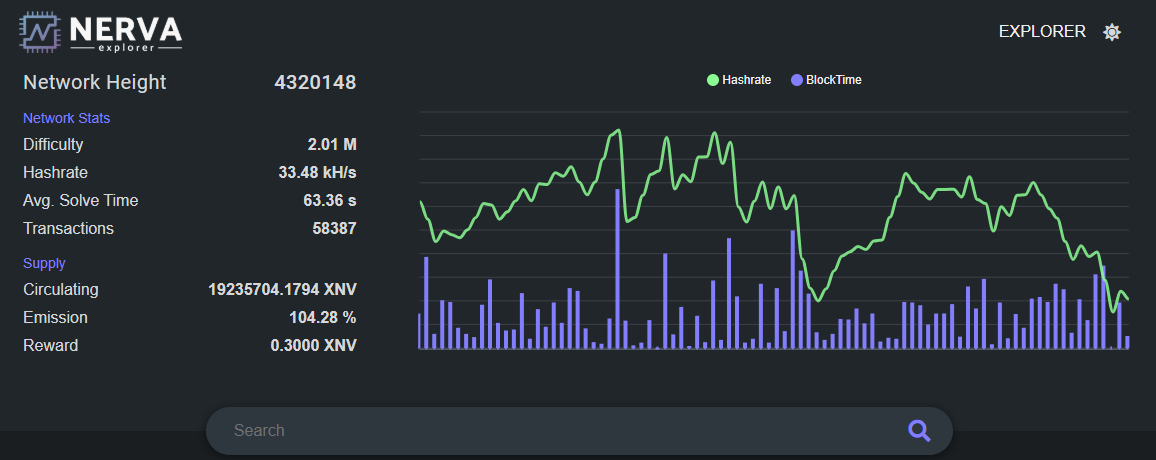
Hashrate: ~400 – 800 kH/s before the fork, now stabilized between 25 and 40 kH/s
Difficulty: 30M+ before, now around 2M+
Block time: back to roughly 60 seconds, right on target
That’s over a 90% drop in the reported hashrate, which is almost exactly what we predicted before the fork. The number is smaller because each hash on the new algorithm does far more work. CNA v6 uses an 8 MB scratchpad, generates a fresh random program every block, and forces each memory access to depend on the previous one. Same hardware, same effort, far fewer hashes per second.
Hard forks go badly when nobody’s ready. This one had a two week runway, and the ecosystem used it.
Every centralized service integrated with Nerva upgraded to v0.3.0.0 before the fork: the exchanges (NonKyc, CexSwap, NoirTrade), the explorer and API, TipBot, NerVault, NervaQuest, and coinQuests. That meant no service downtime and nothing for their users to do.
Node adoption climbed steadily too, from 19% in the first two days after release to 69% by fork day. Most miners and node operators paid attention, and it showed.
What Hard Fork 13 actually changed
CryptoNight-Adaptive v6. The new Proof of Work keeps mining on ordinary CPUs and pushes back hard against ASICs, FPGAs, and GPUs. The larger scratchpad moves the working set out of CPU cache and into main memory, and the dependent access pattern stops fast chips from hiding memory latency. The practical result is that a high end machine can’t run away with the network the way it can elsewhere, and modest hardware stays competitive.
Privacy and consensus hardening. Transaction validation is stricter now, including a minimum output rule and tighter requirements on the outputs referenced by ring signatures.
Missed the upgrade?
If your node ran through the fork on an old version, it’s on the wrong chain, but it’s fixable.
Pop blocks back below the fork height with nervad --pop-blocks X, where X is your current height minus 4,320,000, plus about 10 for safety. In NervaOne, use Daemon Setup > Restart with Optional Command and enter --pop-blocks X.
Your node will resync onto the correct chain from there. Popping a few extra blocks does no harm.
What’s next
Work on Hard Fork 14 has already started. The plan includes CLSAG and Bulletproofs+ (smaller, faster transactions with the same privacy), a ring size increase for a larger anonymity set, and potentially CryptoNight-Adaptive v7 to even out per-core hashrate further across different CPUs. No fork heights are set, and nothing changes until they are.
The direction is the same as it’s always been: close the privacy gap with Monero while keeping what makes Nerva different, solo CPU mining with no pools and no central authority. 1 CPU = 1 Vote.
Thank you
This went well because the community made it go well. People developed, tested, reported issues, upgraded their nodes, and nudged the stragglers. Contributors wrote the code, reviewed it, and shipped it.
Nerva has always stood for one CPU, one vote. With HF13 live, reality moved a lot closer to that vision.
If you’re watching Nerva’s network hashrate around Hard Fork 13, brace yourself for a big drop. Right after the fork, net hashrate is going to fall sharply, we expect around a 90% drop, from 400 – 800 kH/s in the last few months to somewhere around 50 kH/s afterwards.
Before anyone panics: this is expected, it’s healthy, and it does not mean the network got weaker. Here’s exactly what’s happening and why.
The short version
Hashrate measures how many hashes the network computes per second. Hard Fork 13 replaces the mining algorithm with CryptoNight-Adaptive v6, and each hash on the new algorithm does far more work than a hash on the old one. So the same computers, working just as hard, produce far fewer hashes per second.
The number goes down because the unit changed, not because the network lost security or miners.
Why each hash is now so much heavier
Three things make a CNA v6 hash much more expensive to compute than the old algorithm:
A 4x larger scratchpad. The old algorithm used a 2 MB memory buffer per hash. CNA v6 uses 8 MB. Every single hash now has to work through four times as much memory.
A random program per block. Instead of one fixed calculation, each block runs a freshly generated program of hundreds of instructions, executed thousands of times. That’s a lot more computation packed into every hash.
Dependent memory access. The algorithm is built so each memory step depends on the result of the one before it. Your CPU can’t run ahead or do the work in parallel, it has to wait for each step, which deliberately slows each hash down.
Add those together and a single hash takes far longer than it used to. If each hash takes roughly ten times as long, the hashes-per-second number falls by about ninety percent. Same hardware, same effort, much heavier hash.
Comparing the two numbers is apples to oranges
This is the key thing to understand: you cannot compare hashrate across two different algorithms. It’s like comparing miles per hour to laps per hour. A lower number on a longer track doesn’t mean you slowed down.
500 kH/s on the old algorithm and roughly 50 kH/s on the new one represent a similar amount of real work being done by a similar set of machines. The headline number shrank because each hash now counts for a lot more.
What about network security?
A smaller hashrate number does not make Nerva easier to attack. Security comes from how expensive it is to out-compute honest miners on the same algorithm, and CNA v6 is more expensive and more resistant to specialized hardware than the old algorithm, not less.
In fact, the new algorithm strengthens security in ways the raw number doesn’t show. The large memory requirement and random program are specifically designed to shut out ASICs, FPGAs, and GPUs, keeping mining on general-purpose CPUs where it stays widely distributed. An attacker can’t just buy specialized machines to overpower the network. They’d have to out-CPU everyone else, on an algorithm built to keep any single machine from running away with it.
What miners will notice
Your personal hashrate number will drop too, and that’s completely normal. What matters is your share of the network, and everyone’s numbers drop together, so your slice, and your rewards, stay proportional.
A few other things to expect:
Block times stay normal. Difficulty automatically readjusts to the lower hashrate, so blocks keep coming at about 60 seconds.
Un-upgraded miners fall off the real chain until they update to v0.3.0.0.
Bottom line
When you see Nerva’s hashrate drop around 90% at Hard Fork 13, that’s the algorithm change doing exactly what it’s supposed to. The number is smaller because each hash is much bigger. The network is just as secure, more resistant to specialized hardware, and still mined by everyday CPUs the way Nerva is meant to be.
Nerva has always stood for one CPU, one vote. With HF13, reality just moved a lot closer to that vision.
If you haven’t upgraded yet, do it before the fork at block 4,320,000 so you don’t miss a beat: https://nerva.one/#downloads
Let’s not sugarcoat this. XeggeX stole from its users, we were one of them, and anyone still trusting this exchange is walking into the same fire that already burned the rest of us. This is not a “be careful” post. This is a “stay away, full stop” post.
Here is the whole story, and what these people are doing right now to find their next victims.
This post is an updated version of our earlier XeggeX warning:
December 2023. Nerva ($XNV) was listed on XeggeX, back when it was up and coming exchange for low-cap coins.
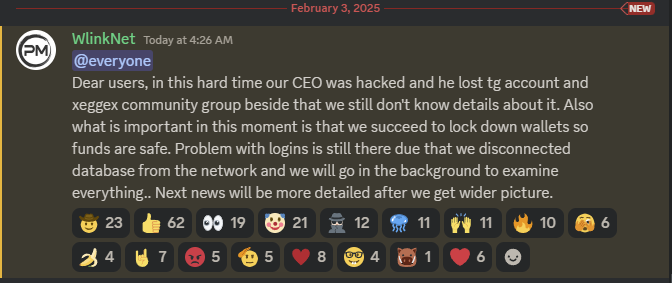
February 2025. XeggeX went dark. The operator, “Karl,” rolled out the oldest excuse in the book: we got hacked. The site came back weeks later, but balances were gone. In their place, IOUs for major coins and a promise that everyone would be made whole.
Then the site vanished, and so did the money. That “hack” was the cover story for a rug. Users were left with nothing but screenshots of balances they will never see again. We know, because we lost real money in it.
Call it what it is: theft.
The fake “refund” act
After laying low, the operators crawled back.
January 2026. They started stirring again in their Discord.
February 15, 2026. The old XeggeX X account announced that “refunds” were being processed. That post has since been deleted by @xeggex account.
Do not fall for it. An operation that already made everyone’s money disappear does not suddenly rediscover its conscience. The refund talk exists for one reason: to rebuild just enough hope to lure people, and fresh deposits, back in. If you actually believe you’re getting a refund from XeggeX, nothing in this post is going to save you.
What they’re doing right now: the airdrop bait
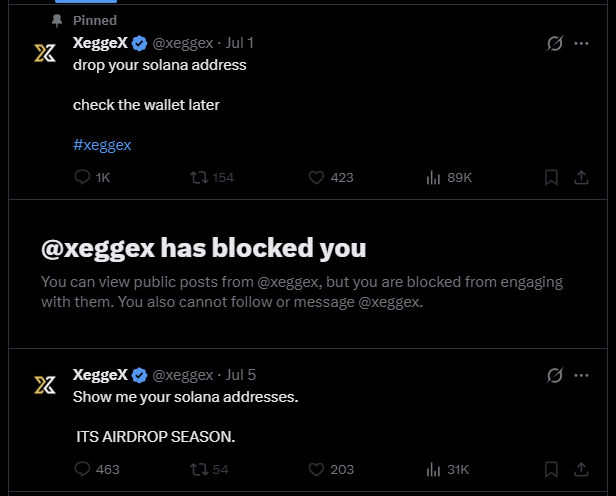
The latest hustle is pure recruitment. XeggeX is spamming “airdrop” hype and telling people to hand over their Solana wallet addresses:
“drop your solana address, check the wallet later”
“Show me your solana addresses. ITS AIRDROP SEASON.”
There is no airdrop. Begging strangers for wallet addresses is how scammers build victim lists and steer people to wallet-draining sites and fake “claim” pages, where one signature empties your wallet. A real exchange does not run its business panhandling for wallet addresses in X replies.
And watch what they do to anyone who warns you: when we called them out, XeggeX blocked us. That’s the tell. Scammers block the people telling the truth because honesty kills their recruitment. The block isn’t defensive, it’s part of the con.
So burn this in: never send funds to XeggeX, never give them your wallet address, and never connect a wallet, install any app from them or sign anything for a XeggeX “airdrop.” The airdrop is the hook. You are the fish.
People are STILL losing funds
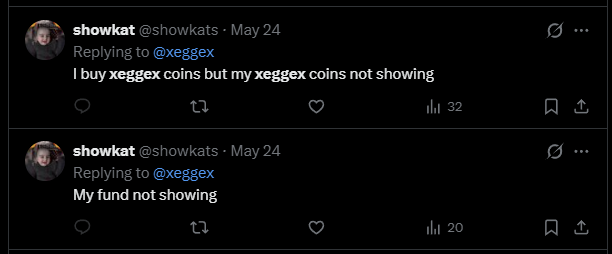
This isn’t ancient history that got cleaned up. As recently as May 24, 2026, users were publicly begging XeggeX for their money:
“I buy xeggex coins but my xeggex coins not showing”
“My fund not showing”
Months after the “refunds” supposedly started, real people are still locked out of real funds. That’s the truth sitting underneath all the airdrop noise.
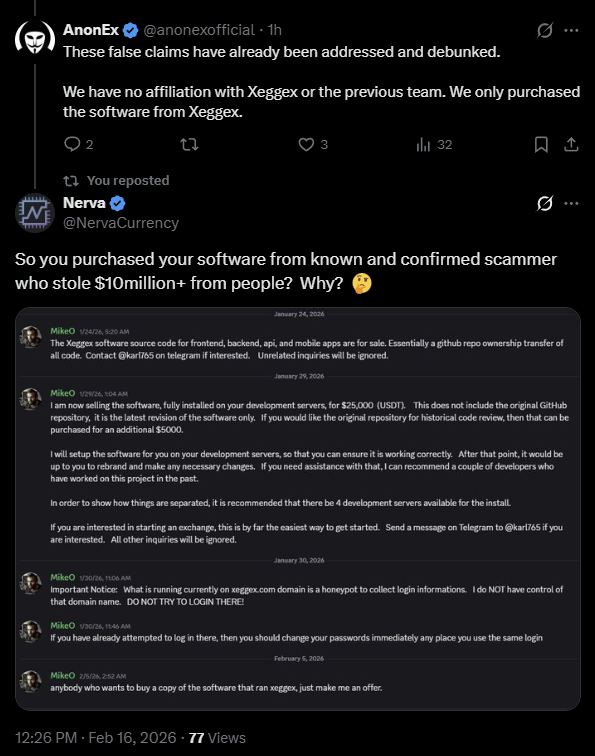
AnonEx: XeggeX’s second act, admitted out loud
AnonEx tried to wave us off, posted from their own account: “We have no affiliation with Xeggex or the previous team. We only purchased the software from Xeggex.”
Read that again, because they admitted it themselves. They bought their exchange software directly from XeggeX, the operation that stole over $10 million from its users. Our reply was the only question that matters: why would anyone buy their platform from a known, confirmed scammer?
Then AnonEx vanished, right on cue:
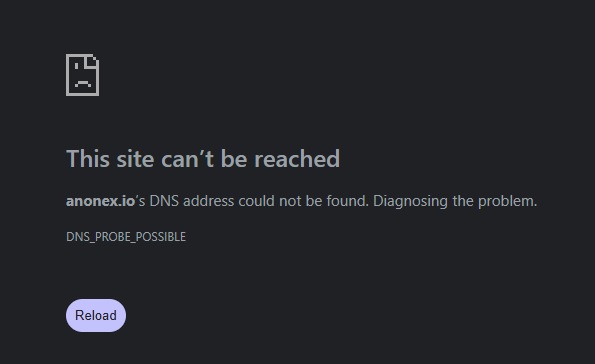
Its official X account, @anonexofficial, no longer exists.
Its website, anonex.io, is dead. The domain doesn’t even resolve.
Same code, same crew, same rug. If you had anything on AnonEx, it’s gone. This is what happens every single time: when a “new” exchange proudly runs a known scammer’s code, it isn’t a new exchange. It’s the next rug.
A warning for every past XeggeX user: do not log into xeggex.com
Here’s something every former XeggeX user needs to hear. Alongside those code-sale messages, a serious warning has been circulating: that the current xeggex.com is now a honeypot set up to harvest logins, with people urged not to enter their credentials and to change any reused passwords.
We can’t independently confirm who controls that domain today, but the precaution costs you nothing and the downside of ignoring it is severe:
Do not enter your login on xeggex.com.
If you ever used XeggeX and reused that email and password anywhere else, change those passwords now, especially your email, other exchanges, and anything financial.
They already took people’s funds. Don’t hand them your credentials too.
Know the playbook
XeggeX and AnonEx ran the same script, and so do most exchange scams. If you see these signs, walk away:
A convenient “hack” that just happens to wipe user balances, followed by IOUs and vague promises.
Going dark, then reappearing with fresh promises of refunds or rewards.
“Airdrops” that want your wallet address, a wallet connection, or a signature.
Buying or running a known scammer’s code and branding it a “new” exchange.
Blocking and silencing critics instead of answering them.
Anonymous operators with zero accountability when the money disappears.
Hold your own keys. Only use exchanges with a real, verifiable track record, and never leave more on any exchange than you’re actively trading. If a “gift” needs your wallet or a signature, it’s a robbery with a bow on it.
We’re not letting this go
We got rugged by XeggeX, and we’re not going to sit quietly while they and their spinoffs line up the next round of victims. We warned everyone about the airdrop bait, we’ve documented AnonEx, and we’ll keep publishing every scam we uncover. These people count on short memories and silenced critics. They’re going to get neither from us.
If XeggeX, AnonEx, or any operation like them burned you too, speak up and share it. Come tell us: