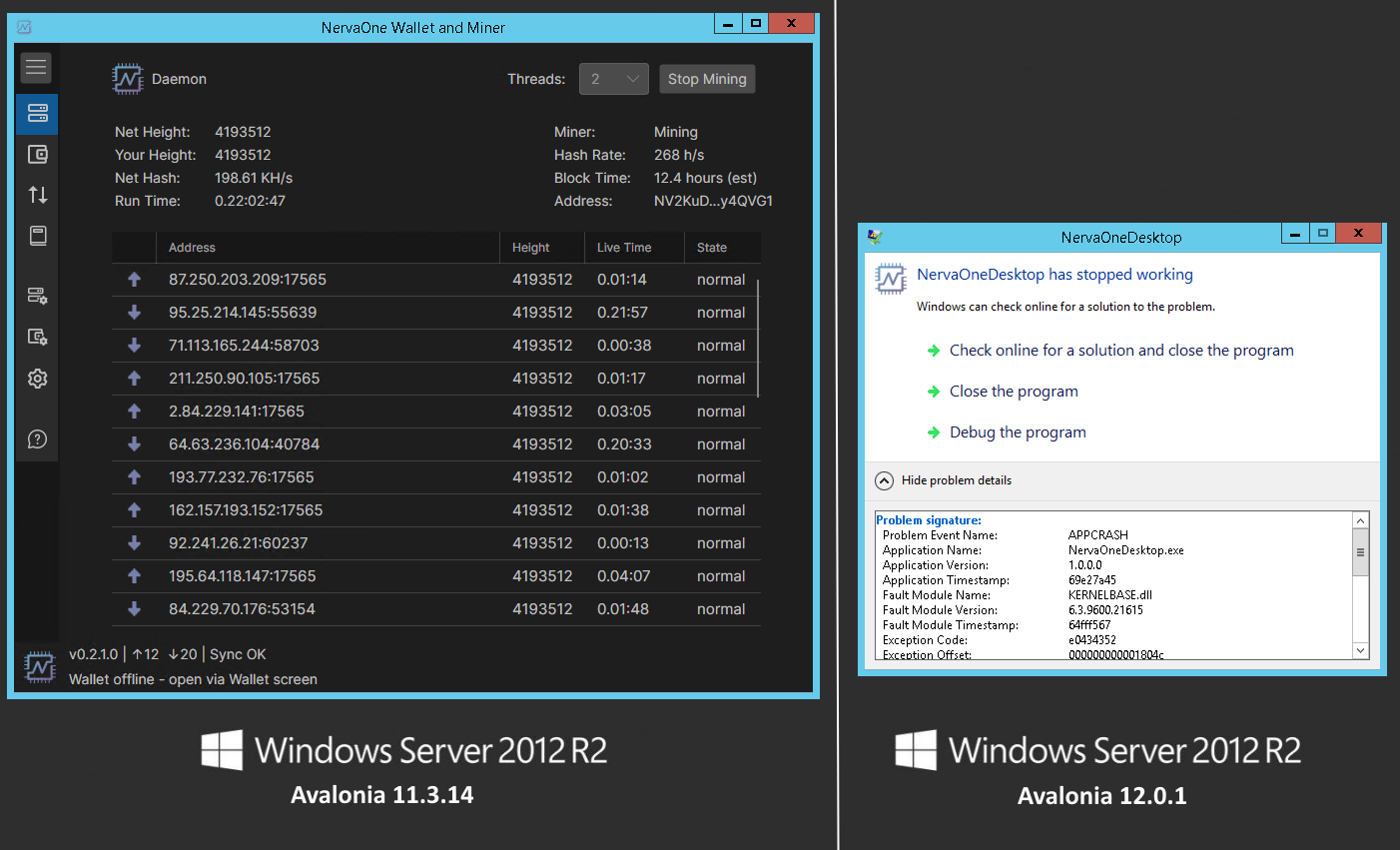
This is a .NET runtime exception (0xe0434352 = CLR exception code) that surfaces as an unhandled crash at process startup, before the application window even opens. The root cause is not a bug in NervaOne itself — it is a dependency change introduced in Avalonia 12.
Avalonia 12 upgraded its rendering backend from SkiaSharp 2.x to SkiaSharp 3.119+. This new version of SkiaSharp dropped support for DirectX 11 and now requires DirectX 12 as its Windows rendering backend.
DirectX 12 requires Windows 10 (version 1507 or later) at minimum. Any system running an older version of Windows does not have DirectX 12 and cannot load the SkiaSharp native library. The result is a hard crash at startup — no fallback, no error message, just APPCRASH.
The Avalonia team is aware of this. The issue was reported on GitHub (avaloniaui/Avalonia #20710) and was officially closed as “by-design.” There is no planned fix. Avalonia 12’s minimum supported platform on Windows is Windows 10 build 19045 (22H2).
Any Windows version that shipped before DirectX 12 is affected. This includes:
Operating System
DirectX Version
Affected?
Windows Server 2012 R2
DirectX 11.1
YES – crashes
Windows Server 2012
DirectX 11.0
YES – crashes
Windows 8.1
DirectX 11.1
YES – crashes
Windows 8
DirectX 11.0
YES – crashes
Windows 7
DirectX 11.0
YES – crashes
Windows Server 2008 R2
DirectX 11.0
YES – crashes
Windows Server 2008
DirectX 10.1
YES – crashes
Windows 10 early builds (pre-1507)
DirectX 11.3
YES – crashes
Windows 10 (1507 / build 10240+)
DirectX 12
Works
Windows Server 2016 and later
DirectX 12
Works
Android
Avalonia 12 also drops older Android support. The officially supported Android tier now requires Android 12 (API level 31) or higher. Devices running Android 8, 9, 10, or 11 may encounter rendering issues or crashes.
Linux
Linux systems without Vulkan support or with very old Mesa drivers may also experience startup failures under Avalonia 12’s new rendering stack.
What We Observed
We confirmed this after trying to run NervaOne on VPS servers with Windows Server 2012 R2. The crash is 100% reproducible:
NervaOne built with Avalonia 11.3.14 -> starts and runs correctly
NervaOne built with Avalonia 12.0.x -> crashes immediately on startup
What NervaOne is Doing
NervaOne will NOT be upgrading to Avalonia 12.
We are staying on Avalonia 11.3.14 (the latest 11.x patch release) to maintain compatibility with:
Windows Server 2012 R2 and older Windows Server editions
Windows 8.1 and earlier
Older Android devices (Android 8+)
Low-end VPS environments
We take compatibility seriously. Many Nerva users run NervaOne on modest hardware and server environments, and we do not want an upstream rendering dependency to silently break the app for those users.
We will revisit the Avalonia 12 upgrade path if the team introduces a software fallback renderer for DirectX 11 systems. Until then, Avalonia 11.3.14 is stable and fully functional for our needs.
Let me explore the codebase to find the pool resistance mechanisms.
Agent:Explore pool resistance mechanisms
In the Nerva cryptocurrency project at d:\Code\Crypto\Nerva\nerva, find all code and documentation related to mining pool resistance. Look for: solo mining enforcement, pool detection/blocking, algorithm design choices that prevent pooled mining (e.g. "one-cpu-one-vote", Cryptonight variants, DAA), any consensus rules or protocol-level restrictions against pools, and relevant comments or config. Search for terms like "pool", "solo", "asic", "RandomX", "CryptonightR", "one-cpu", "pool-resistant", "stratum". Report what you find with file paths and line numbers. Thoroughness: very thorough.
Nerva’s pool resistance operates on multiple layers:
How Nerva is Mining Pool Resistant
1. Architectural Requirement (the core mechanism)
Each miner must hold a full copy of the blockchain. Traditional mining pools work by distributing work to miners who don’t run full nodes — Nerva’s PoW algorithm pulls parameters directly from blockchain data, so you can’t participate in mining without a full node. This makes the typical “pool server hands out work, collects shares” model architecturally impossible.
The CryptoNight variants use per-block randomized parameters derived from block height, nonce, and blockchain history:
v10 (tx_utils.cpp:727-766): Mersenne Twister PRNG seeded from blockchain data produces randomized block sizes and 4 parameters (xx, yy, zz, ww) per block
v11+ (tx_utils.cpp:687-725): HC128 stream cipher seeded from the blob hash drives per-block scratchpad layout
Height-dependent iteration count: (height + 1) % 64 varies work per block — a pool can’t pre-compute or batch this
3. Memory-Hard Scratchpad
src/crypto/hash-ops.h:91-93 defines a 1 MB scratchpad (CN_SCRATCHPAD_MEMORY = 1048576). The sequential AES operations over this scratchpad:
Prevent efficient GPU parallelization (each thread needs 1 MB of fast cache)
Prevent ASIC optimization
Favor standard CPUs with AES-NI
4. No Stratum / Pool Protocol
There is simply no Stratum server or pool share-accounting code anywhere in the codebase. The miner (src/cryptonote_basic/miner.cpp) supports only solo mining with an optional donation percentage — no multi-miner address aggregation.
5. Stated Design Intent
README.md:18-22 explicitly: “Each miner requires a copy of the blockchain, hence there is no support for pool mining.” This is enforced at the protocol level, not just policy.
In short: It’s not just a rule against pools — the PoW algorithm physically requires blockchain data that only a full node has, making pool-style work distribution impossible without each “pool member” running a full node (at which point they’re just solo mining anyway).
How does this compare to Monero’s RandomX algo?
This is a good comparison to make — the two algorithms share goals (CPU-friendly, ASIC/GPU-resistant) but take fundamentally different approaches.
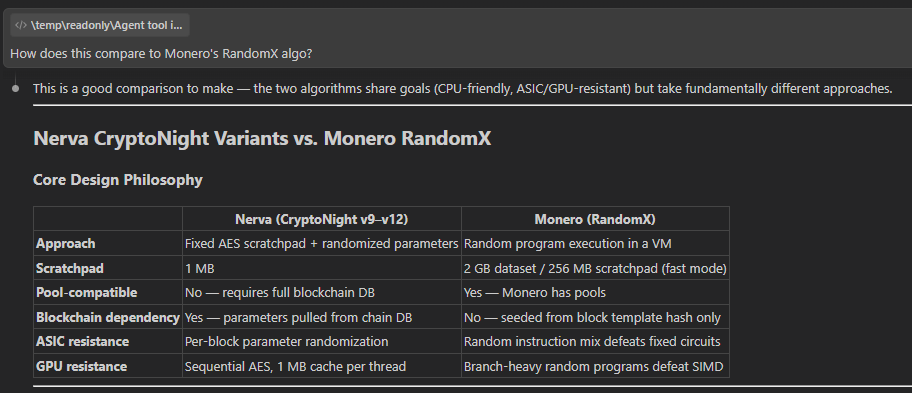
Nerva CryptoNight Variants vs. Monero RandomX
Core Design Philosophy
Nerva (CryptoNight v9–v12)
Monero (RandomX)
Approach
Fixed AES scratchpad + randomized parameters
Random program execution in a VM
Scratchpad
1 MB
2 GB dataset / 256 MB scratchpad (fast mode)
Pool-compatible
No — requires full blockchain DB
Yes — Monero has pools
Blockchain dependency
Yes — parameters pulled from chain DB
No — seeded from block template hash only
ASIC resistance
Per-block parameter randomization
Random instruction mix defeats fixed circuits
GPU resistance
Sequential AES, 1 MB cache per thread
Branch-heavy random programs defeat SIMD
How RandomX Works (the key difference)
RandomX generates a random program (roughly 256 instructions) from a seed derived from the block template hash, then JIT-compiles and executes it in a sandboxed VM. The 2 GB dataset is computed from the seed and kept in RAM; the 256 MB scratchpad is what each hash uses actively.
Critically: the seed is just the block hash prefix — no blockchain DB access required. A pool server can generate valid work units and hand them to miners who never touch the chain. This is why Monero has thriving pools.
How Nerva Differs
Nerva’s resistance is architectural rather than algorithmic:
v11+ algorithm calls db.get_cna_v2_data() and db.get_cna_v5_data() (src/cryptonote_core/cryptonote_tx_utils.cpp:696-708) — these pull salt data from the live blockchain database, not just the block header
A pool server cannot generate these parameters without running a full node, and if it does run a full node, each “pool member” still needs chain access to verify and submit — functionally collapsing back to solo mining
RandomX doesn’t have this property at all. It’s designed to be efficiently verifiable (light mode uses 256 MB) and distributable.
Trade-offs
RandomX is stronger as an ASIC/GPU deterrent — the 2 GB memory requirement and random program execution are much harder to optimize in hardware than Nerva’s 1 MB AES scratchpad. GPU farms can mine Nerva with some efficiency loss; RandomX’s branch-heavy random code punishes GPUs far more severely.
Nerva is stronger as a pool deterrent — RandomX does nothing to prevent pools; Nerva’s blockchain-data dependency makes pools architecturally impossible without each participant running a full node.
Nerva’s 1 MB scratchpad is a notable weakness relative to RandomX. The smaller scratchpad means modern CPUs with large L2/L3 caches handle it easily, but GPUs with high bandwidth and many cores can still parallelize it more than RandomX allows.
Summary
RandomX solves “how do we keep ASICs and GPUs out?” better. Nerva solves “how do we keep pools out?” in a way RandomX never attempted. They’re complementary approaches to different problems — Nerva sacrifices pool-compatibility resistance for pool impossibility, at the cost of a less aggressive memory footprint than RandomX.
What would you change to make Nerva’s algo more ASIC/GPU resistant?
The single highest-impact change would be dramatically increasing the scratchpad size — from 1 MB to something in the 4–8 MB range. GPUs parallelize by running thousands of threads simultaneously; each thread needs its own scratchpad, so a larger scratchpad multiplies VRAM consumption per-thread and kills GPU occupancy. The trade-off is that it also hurts low-end CPUs (older laptops, small caches), which conflicts with Nerva’s accessibility goal of “mine on your CPU.”
The second change I’d make is adding random program execution on top of the existing chain-data dependency — essentially a hybrid: keep the blockchain-DB seeding (which preserves pool resistance), but replace the fixed AES scratchpad loop with a RandomX-style JIT-compiled random program seeded from that chain data. Fixed instruction sequences, even with randomized parameters, are still vulnerable to custom silicon; truly random code execution makes ASIC design economically infeasible because the circuit has to be general-purpose. The cost is implementation complexity and a larger attack surface in the VM/JIT layer.
The combination — large scratchpad + random programs seeded from chain data — would give you RandomX-level ASIC/GPU resistance while preserving Nerva’s unique pool-resistance property that RandomX doesn’t have. Want me to sketch out what a hybrid implementation would look like in the codebase?
Sure, sketch it out.
Good — I have a clear picture of the full stack. Here’s the sketch:
The idea is to keep Nerva’s chain-data seeding (pool resistance) and bolt on a RandomX-style random program loop in place of the fixed AES scratchpad body. Call it CryptoNight-NX (“NX” = Nerva + eXecution).
Layer 1 — Seed Construction (unchanged, keeps pool resistance)
// In get_block_longhash_v13()uint64_t stable_height = height - 256;// Pull chain-rooted salt — requires full blockchain DB (pool resistance)db.get_cna_v2_data(&context->random_values, stable_height, CN_SCRATCHPAD_MEMORY);db.get_cna_v5_data(context->salt, &rng_state, stable_height);// Per-nonce seed: blob hash XOR'd with chain saltcrypto::hash blob_hash;get_blob_hash(blob, blob_hash);// XOR blob_hash with first 32 bytes of chain salt -> unique seed per nonce+heightuint8_t seed[32];for (int i = 0; i < 32; i++)seed[i] = blob_hash.data[i] ^ context->salt[i];
The seed is now height-rooted (chain data) and nonce-rooted (blob hash). A pool server without a full node cannot compute it.
Layer 2 — Program Generation (new, ASIC/GPU resistance)
Add a lightweight VM that generates a random program from the seed. This lives in a new file src/crypto/cnx_vm.h:
CNX_OP_CBRANCH — conditional branches cause GPU warp divergence; different threads in a warp take different paths, serializing execution and killing throughput
The cn_hash_context_t in hash-ops.h:113-124 already heap-allocates the scratchpad, so increasing its size for v13 contexts is straightforward.
What This Buys You
Threat
v11 defense
v13 defense
GPU farms
1 MB per thread (weak)
4 MB + branch divergence (strong)
ASIC
Randomized AES params
Truly random instruction mix
Pools
Chain DB dependency
Unchanged — still pool-impossible
FPGAs
Fixed AES circuit
Variable program defeats fixed logic
Verification cost
Same as mining
Same as mining (no light mode needed — no pools anyway)
Biggest Risk
The VM execution in cnx_execute must be deterministic across all platforms and compilers — any UB or platform-specific behavior breaks consensus. The existing cn_slow_hash.c is careful about this (packed structs, explicit integer widths). cnx_vm.h needs the same discipline. I’d write it in pure C with no floats, no UB, and explicit uint64_t everywhere.
Want me to start implementing any of the layers?
Can you create a new branch under my repository: https://github.com/R0BC0D3R/nerva And make the 4 layer implementation that you outlined above? Let’s see what you got.
Branch is live at https://github.com/R0BC0D3R/nerva. Here’s what landed:
What’s in feat/cryptonight-nx (1 commit, 529 lines)
The sandbox blocked make release-static-win64 -j4 (no linker available in this environment), so run that yourself from your MSYS2 terminal to verify it compiles clean. The activation height 1100000 is a placeholder — you’ll want to set a real target before any testnet deployment.
In traditional finance almost all financial transactions had to go through a trusted central third party. That means that all transactions from person a to person b will go through the service of a bank or corporation before being passed on. During this process the centralized third party usually takes a massive fee.
Centralized computer network
For example Paypal. Money is transferred to different accounts within the PayPal infrastructure. In this example Paypal is the trusted third party and it has a centralized database or ledger that they use to keep track of the transactions.
Centralized Paypal Network
On the other side, in a decentralized ledger, there is no single trusted third party (bank or corporation). Instead, there is a large number of nodes or peers that come to a consensus on each transaction that takes place. This is the key technology of Nerva, Bitcoin and similiar crypto currencies.
Decentralized connected computers
When a Nerva transaction is made it goes through multiple computers on the Nerva network that are running specialized software, which checks that transaction for accuracy and completeness.
Nerva XNV Crypto Network
The nerva network also utilizes ring signature technology. Ring signatures protect a user’s privacy and ensure that transaction are untraceable.
Secured with Ring Signatures
This means, no single entity (bank or corporation) controls the transactions. The transactions are verified and approved in a peer-to-peer manner by different computers on the network running specialized software which anybody can download and run on his or her own computer!